South Asians are a two way mixture of West Eurasians and a people(s) distantly related to East Asians known as ASI. ASI is more likely to be the native population of South Asia and West Eurasians probably arrived in multiple waves from the NorthWest. A decisive majority of India's mtDNA is ASI but a big chunk is West Eurasian. In this post I’ll look at West Eurasian mtDNA in South Asia to gain insight into who their maternal West Eurasian ancestors were.
Bronze age European Steppe+Neolithic Iran
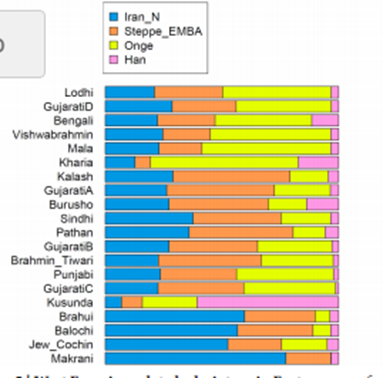
Lazaridis 2016 successfully modeled South/Central Asians as a mixture of Neolithic Iran, Bronze age Steppe, and East Asians(as a proxy for ASI). The results they got are below.
Y DNA so far is consistent with this idea. The most common West Eurasian yHGs in South Asia are R2, R1a-Z93, J2, and G. R2, J2, and G have been found in ancient Iran. R1a-Z93 has been found in the Bronze age European Steppe.
Y DNA so far is consistent with this idea. The most common West Eurasian yHGs in South Asia are R2, R1a-Z93, J2, and G. R2, J2, and G have been found in ancient Iran. R1a-Z93 has been found in the Bronze age European Steppe.
mtDNA is also consistent with this model. A large percentage, almost 50%, of South Asia’s West Eurasian mtDNA belongs to mHGs found in remains from Neolithic Iran and the Bronze age Steppe. I still think we should be open to more complex origins of South Asians’ West Eurasian ancestry though.
Mostly Middle Eastern with a dose of European?
mHG Frequencies: Haplogroup Frequencies of West Eurasian mtDNA in India and a few other South Asians. Clade Origins: Deep subclades of West Eurasian haplogroups found in India and where in West Eurasia they’re most common.
Clade Origins: Deep subclades of West Eurasian haplogroups found in India and where in West Eurasia they’re most common.
Clade Origins: Deep subclades of West Eurasian haplogroups found in India and where in West Eurasia they’re most common.
The region of West Eurasia India shares the most mtDNA with is first Iran and second the rest of the Middle East. U7, U1, HV2, HV14, R0a, R2, J1b1b, J1b3, J1d are Middle Eastern-specific lineages found in India. Most of them peak around Iran. U7 is by far the most common. It’s more common, when not counting ASI, than anywhere in the Middle East.
A string of European-like mtDNA exists in South Asia aswell especially in Afghanistan and Pakistan. U5a, U4, U2e, J1b1a1, T1a1, J2b1a, J1c, T2b all have a consistent presence throughout South Asia. U5a1a1, U5a1b are the main U5a1 clades in Europe aswell as South Asia. U5a and U4, which are two of the three most common European-like mtDNAs in South Asia, today peak in NorthEast Europe, Siberia, Scandinavia, and YugoSlavia.
On average about 18% of India’s West Eurasian mtDNA belongs to those European-specific subclades and about 44% belongs to the Middle Eastern-specific subclades I listed earlier. SC Asia(Afghanistan, Pakistan) has significantly less Middle Eastern-specific mtDNA and slightly more European-specific mtDNA.
South Asian mtDNA also has trends and haplogroups which aren’t comparable to anything in West Eurasia. There are subclades of West Eurasian haplogroups specific to South Asia; H2b, U7a3b, U7a7, U7a6, U7c, U5a1g, and several W subclades. mHG X, which has a presence in all of West Eurasia and parts of North America, is non existent in South Asia. In contrast mHG W is extraordinarily more popular than anywhere in West Eurasia.
Matches with Ancient West Eurasians
There are many interesting examples of modern South Asian mtDNA belonging to the same subclades as ancient West Eurasian. Examples are listed at at the bottom.
Kalash mtDNA in particular has lots matches with the Bronze age European Steppe. It’s mostly madeup of a four founder effects. 3 of 4 are typical of the Bronze age European Steppe. The only two Kalash mtDNAs I found that weren’t apart of these founder effects belonged to U4b1a4 and T2a1a, both of which have been found in the Bronze age European Steppe.
Two other interesting matches were found between the Bronze age European Steppe and modern SC Asia. I possess over 1,000 H mito-genomes and the only H2bs in my collection are from an ancient Yamnaya individual and several modern SC Asian individuals. U5a1g today is mostly in Iran and SC Asia but an ancient Corded Ware individual from Germany belonged to it as well.
R2: 1.5% in India, 6% in SC Asia.
Neolithic Iran, 8000-7700 BC.
HV2: 2.4% in India, 1% in SC Asia.
Neolithic Iran, 9100-8600 BC.
R0a: 1% in India, 2% in SC Asia.
Neolithic Levant, 7722-7541 BC
U7a: 20% in India, 9% in SC Asia
Chalcolithic Iran 3956-3796 BC
I1c: Existent in all of SC Asia
Chalcolithic Iran, 3972-3800 BC
U5a1a1: India existent but unknown %, 1% in SC Asia.
Yamnaya Russia 3000 BC,
Afanasievo Siberia 3322-2923 BC
Bell Beaker Germany 2300 BC
U5a1b1: Existent in India.
Corded Ware Germany 2400 BC
Bell Beaker Germany 2500–2050 BC
Bell Beaker Spain 2492-2334 BC
Xijing China(Tarim Mummy) 2000 BC
Unetice Poland 1885-1693 BC
T1a1: India existent but unknown %, 3% in SC Asia.
Potapovka Russia 2125-2044 BC
Srubnaya Russia 1850-1200 BC
Germany 2570-2471 BC
Hungary 2000 BC
Sweden 1200 BC
T2a1a: India existent but unknown %, 1% in SC Asia.
Yamnaya Russia 2887-2634 BC
Sweden 1300 BC
U2e1h: Found in Kalash and Hazara
Potapovka Russia 2200-1900 BC
Sintashta Russia 1960-1756 BC
U4b1a2: Found in Kalash.
Catacomb Russia 2700-2500 BC
U4a1: Found in all South Asian populations.
Neolithic Hungary 5500 BC
Yamnaya Russia 3000 BC
Catacomb Russia 2500-2000 BC
Andronovo Siberia 1746-1626 BC
Corded Ware Germany 2400 BC
H2b: Existent in India and SC Asia
Yamanya Russia 3000 BC
Nice, but it's not Lazardus, but Lazaridis.
ReplyDeleteBtw, any way to be sure if the steppe mtDNA in South Asia is more of the Catacomb kind than the Andronovo-Sintashta kind?
One way is EEFish mtDNA. Andronovo-Sintashta had a decent amount but Catacomb didn't have any(as far we know). EEFish mtDNA does exist in SC Asia. J1c1b1a, J1c5 are in India. J2b1a is a pretty common J clade in SC Asia, it's one of the founder effect haplogroups in the Kalash. Other EEFish mHGs can only be detected with mito genomes.
DeleteThe EEFish mtDNA is not exlucivse to EEF it's also found in Western Asia. So until we get lots of mitogenomes from South Asia mtDNA doesn't favor Catacomb or Andronovo-Sintashta.
I am of the maternal dna haplogroup U1a4. this is also called U1a1d. I am told this is rare because there are only about 5 examples of this sequence in existence that have been discovered and that the origins are probably in Southwest asia 12000-18000 years ago. My general info is: HVR1 matches - U1 France 1, U1 Poland 2, U1 United States 1, U1a4 England 1; HVR1 and HVR2 matches - U1 Poland 1, U1a4 England 1; and HVR1, HVR2, and coding region matches - U1a4 England 1. My rCRS values consist of: HVR1 differences from rCRS - 16092C, 16182C, 16183C, 16189C, 16242T, 16249C, 16294T, and 16362C; HVR2 differences from rCRS - 73G, 263G, 285T, 309.1C, and 315.1C; and coding region differences from rCRS - 750G, 1438G, 2218T, 2706G, 4769G, 4991A, 6026A, 7028T, 7581C, 8848C, 8860G, 11413R, 11467G, 11719A, 12308G, 12372A, 12375C, 12879C, 13104G, 13810A, 14070G, 14364A, 14766T, 15148A, 15326G, and 15954C. My RSRS values, extra mutations are 309.1C,315.1C, 522.1A, 522.2C, T8848C, A11413R, T12375C, G13810A, T16092C, A16182c, A16183c, C16183c, C16294T, and C16519T. I am trying to make sense of all this.
ReplyDeleteI think I know you, UNKNOWN! lol
DeleteI think I know you, UNKNOWN! lol
DeleteI was diagnosed as HEPATITIS B carrier in 2013 with fibrosis of the
ReplyDeleteliver already present. I started on antiviral medications which
reduced the viral load initially. After a couple of years the virus
became resistant. I started on HEPATITIS B Herbal treatment from
ULTIMATE LIFE CLINIC (www.ultimatelifeclinic.com) in March, 2020. Their
treatment totally reversed the virus. I did another blood test after
the 6 months long treatment and tested negative to the virus. Amazing
treatment! This treatment is a breakthrough for all HBV carriers.